
Let’s start with Facebook’s Surveillance Machine, by Zeynep Tufekci in last Monday’s New York Times. Among other things (all correct), Zeynep explains that “Facebook makes money, in other words, by profiling us and then selling our attention to advertisers, political actors and others. These are Facebook’s true customers, whom it works hard to please.”
Irony Alert: the same is true for the Times, along with every other publication that lives off adtech: tracking-based advertising. These pubs  don’t just open the kimonos of their readers. They bring readers’ bare digital necks to vampires ravenous for the blood of personal data, all for the purpose of aiming “interest-based” advertising at those same readers, wherever those readers’ eyeballs may appear—or reappear in the case of “retargeted” advertising.
don’t just open the kimonos of their readers. They bring readers’ bare digital necks to vampires ravenous for the blood of personal data, all for the purpose of aiming “interest-based” advertising at those same readers, wherever those readers’ eyeballs may appear—or reappear in the case of “retargeted” advertising.
With no control by readers (beyond tracking protection which relatively few know how to use, and for which there is no one approach, standard, experience or audit trail), and no blood valving by the publishers who bare those readers’ necks, who knows what the hell actually happens to the data?
Answer: nobody knows, because the whole adtech “ecosystem” is a four-dimensional shell game with hundreds of players…
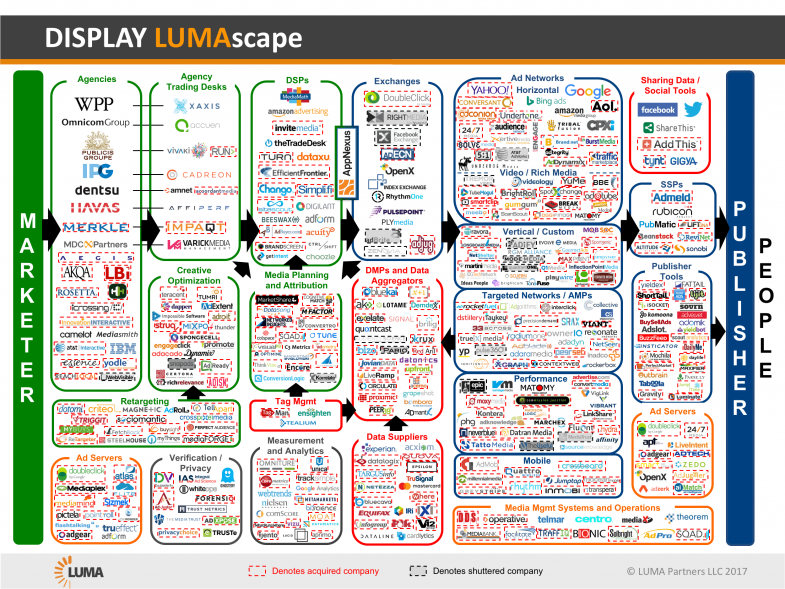
or, in the case of “martech,” thousands:

For one among many views of what’s going on, here’s a compressed screen shot of what Privacy Badger showed going on in my browser behind Zeynep’s op-ed in the Times:

[Added later…] @ehsanakhgari tweets pointage to WhoTracksMe’s page on the NYTimes, which shows this:

And here’s more irony: a screen shot of the home page of RedMorph, another privacy protection extension:
 That quote is from Free Tools to Keep Those Creepy Online Ads From Watching You, by Brian X. Chen and Natasha Singer, and published on 17 February 2016 in the Times.
That quote is from Free Tools to Keep Those Creepy Online Ads From Watching You, by Brian X. Chen and Natasha Singer, and published on 17 February 2016 in the Times.
The same irony applies to countless other correct and important reportage on the Facebook/Cambridge Analytica mess by other writers and pubs. Take, for example, Cambridge Analytica, Facebook, and the Revelations of Open Secrets, by Sue Halpern in yesterday’s New Yorker. Here’s what RedMorph shows going on behind that piece:

Note that I have the data leak toward Facebook.net blocked by default.
Here’s a view through RedMorph’s controller pop-down:
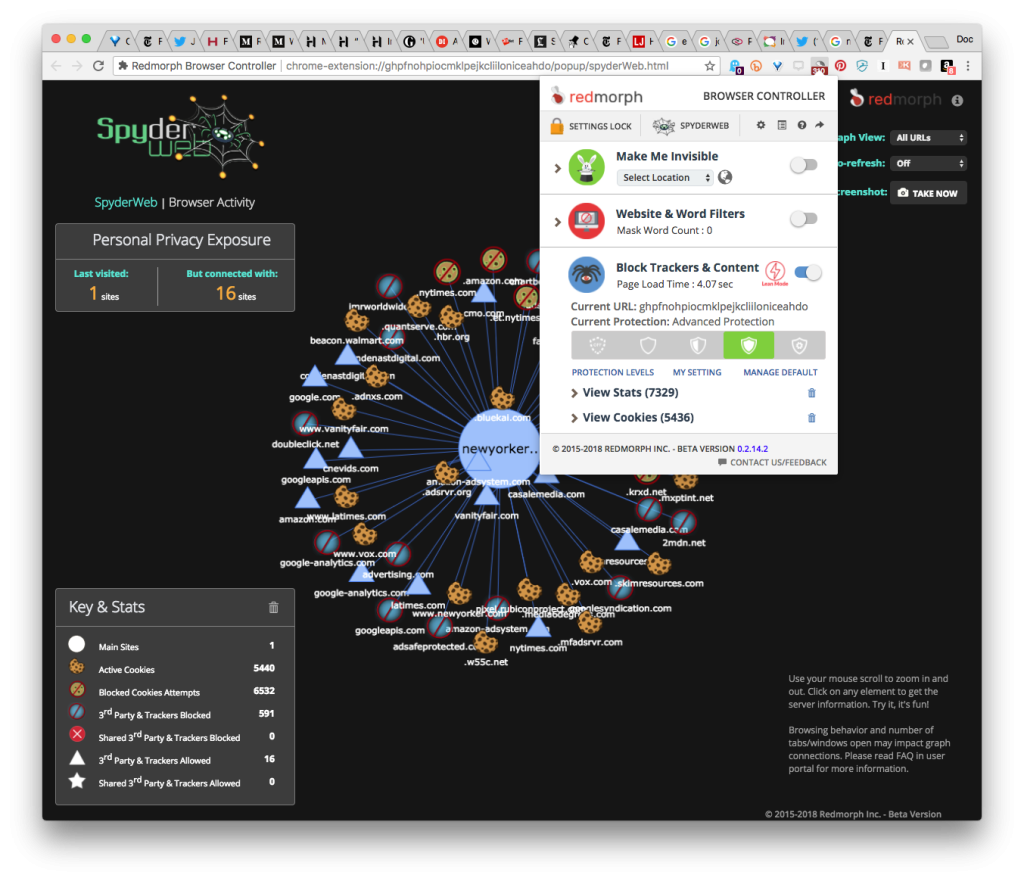
And here’s what happens when I turn off “Block Trackers and Content”:
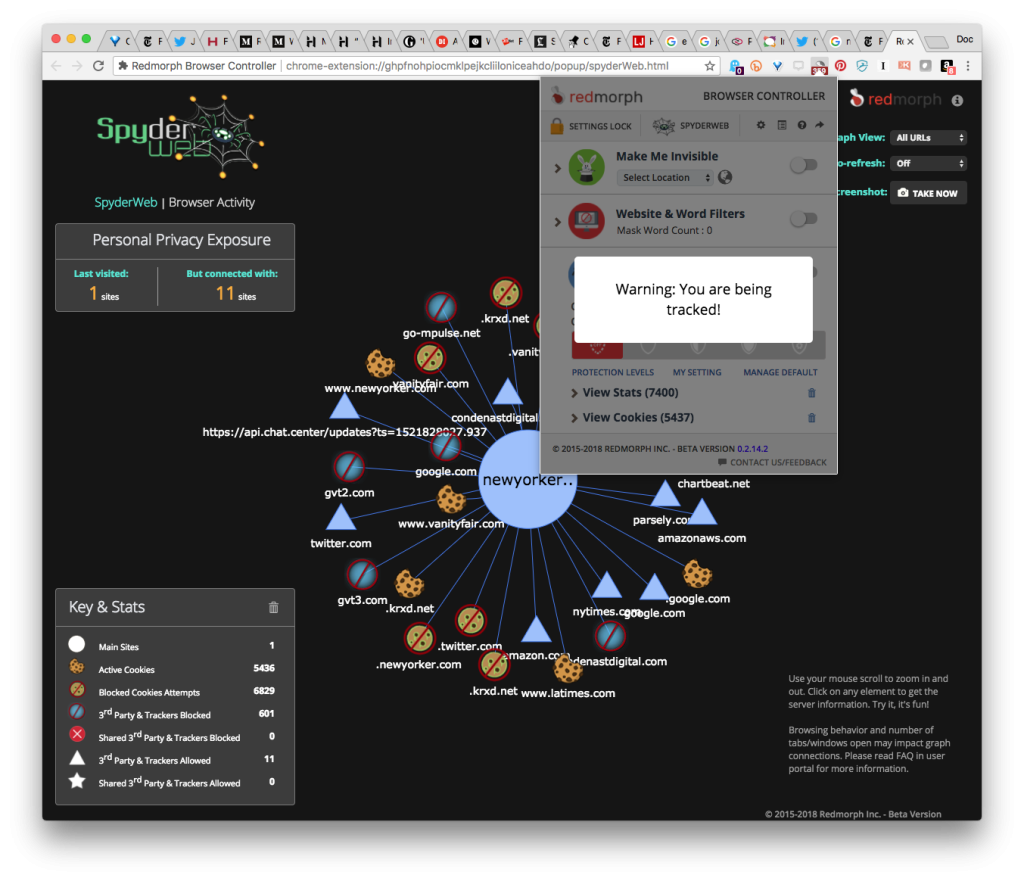
By the way, I want to make clear that Zeynep, Brian, Natasha and Sue are all innocents here, thanks both to the “Chinese wall” between the editorial and publishing functions of the Times, and the simple fact that the route any ad takes between advertiser and reader through any number of adtech intermediaries is akin to a ball falling through a pinball machine. Refresh your page while reading any of those pieces and you’ll see a different set of ads, no doubt aimed by automata guessing that you, personally, should be “impressed” by those ads. (They’ll count as “impressions” whether you are or not.)
Now…
What will happen when the Times, the New Yorker and other pubs own up to the simple fact that they are just as guilty as Facebook of leaking data about their readers to other parties, for—in many if not most cases—God knows what purposes besides “interest-based” advertising? And what happens when the EU comes down on them too? It’s game-on after 25 May, when the EU can start fining violators of the General Data Protection Regulation (GDPR). Key fact: the GDPR protects the data blood of what they call “EU data subjects” wherever those subjects’ necks are exposed in borderless digital world.
To explain more about how this works, here is the (lightly edited) text of a tweet thread posted this morning by @JohnnyRyan of PageFair:
Facebook left its API wide open, and had no control over personal data once those data left Facebook.
But there is a wider story coming: (thread…)
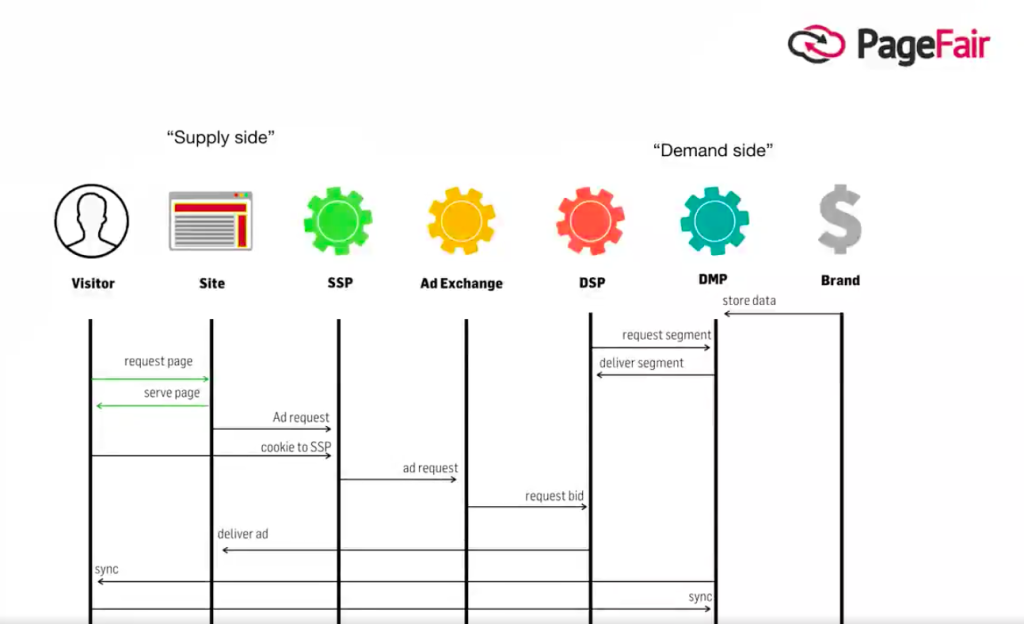
Every single big website in the world is leaking data in a similar way, through “RTB bid requests” for online behavioural advertising #adtech.
Every time an ad loads on a website, the site sends the visitor’s IP address (indicating physical location), the URL they are looking at, and details about their device, to hundreds -often thousands- of companies. Here is a graphic that shows the process.
The website does this to let these companies “bid” to show their ad to this visitor. Here is a video of how the system works. In Europe this accounts for about a quarter of publishers’ gross revenue.
Once these personal data leave the publisher, via “bid request”, the publisher has no control over what happens next. I repeat that: personal data are routinely sent, every time a page loads, to hundreds/thousands of companies, with no control over what happens to them.
This means that every person, and what they look at online, is routinely profiled by companies that receive these data from the websites they visit. Where possible, these data and combined with offline data. These profiles are built up in “DMPs”.
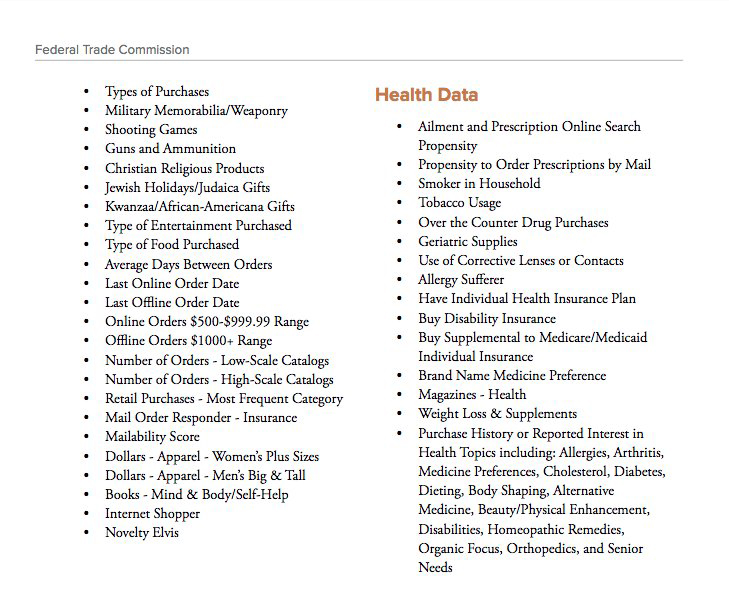
Many of these DMPs (data management platforms) are owned by data brokers. (Side note: The FTC’s 2014 report on data brokers is shocking. See https://www.ftc.gov/reports/data-brokers-call-transparency-accountability-report-federal-trade-commission-may-2014. There is no functional difference between an #adtech DMP and Cambridge Analytica.
—Terrell McSweeny, Julie Brill and EDPS
None of this will be legal under the #GDPR. (See one reason why at https://t.co/HXOQ5gb4dL). Publishers and brands need to take care to stop using personal data in the RTB system. Data connections to sites (and apps) have to be carefully controlled by publishers.
So far, #adtech’s trade body has been content to cover over this wholesale personal data leakage with meaningless gestures that purport to address the #GDPR (see my note on @IABEurope current actions here: https://t.co/FDKBjVxqBs). It is time for a more practical position.
And advertisers, who pay for all of this, must start to demand that safe, non-personal data take over in online RTB targeting. RTB works without personal data. Brands need to demand this to protect themselves – and all Internet users too. @dwheld @stephan_lo @BobLiodice
Websites need to control
1. which data they release in to the RTB system
2. whether ads render directly in visitors’ browsers (where DSPs JavaScript can drop trackers)
3. what 3rd parties get to be on their page
@jason_kint @epc_angela @vincentpeyregne @earljwilkinson 11/12Lets work together to fix this. 12/12
Those last three recommendations are all good, but they also assume that websites, advertisers and their third party agents are the ones with the power to do something. Not readers.
But there’s lots readers will be able to do. More about that shortly. Meanwhile, publishers can get right with readers by dropping #adtech and going back to publishing the kind of high-value brand advertising they’ve run since forever in the physical world.
That advertising, as Bob Hoffman (@adcontrarian) and Don Marti (@dmarti) have been making clear for years, is actually worth a helluva lot more than adtech, because it delivers clear creative and economic signals and comes with no cognitive overhead (for example, wondering where the hell an ad comes from and what it’s doing right now).
As I explain here, “Real advertising wants to be in a publication because it values the publication’s journalism and readership” while “adtech wants to push ads at readers anywhere it can find them.”
Doing real advertising is the easiest fix in the world, but so far it’s nearly unthinkable for a tech industry that has been defaulted for more than twenty years to an asymmetric power relationship between readers and publishers called client-server. I’ve been told that client-server was chosen as the name for this relationship because “slave-master” didn’t sound so good; but I think the best way to visualize it is calf-cow:
 As I put it at that link (way back in 2012), Client-server, by design, subordinates visitors to websites. It does this by putting nearly all responsibility on the server side, so visitors are just users or consumers, rather than participants with equal power and shared responsibility in a truly two-way relationship between equals.
As I put it at that link (way back in 2012), Client-server, by design, subordinates visitors to websites. It does this by putting nearly all responsibility on the server side, so visitors are just users or consumers, rather than participants with equal power and shared responsibility in a truly two-way relationship between equals.
It doesn’t have to be that way. Beneath the Web, the Net’s TCP/IP protocol—the gravity that holds us all together in cyberspace—remains no less peer-to-peer and end-to-end than it was in the first place. Meaning there is nothing about the Net that prevents each of us from having plenty of power on our own.
On the Net, we don’t need to be slaves, cattle or throbbing veins. We can be fully human. In legal terms, we can operate as first parties rather than second ones. In other words, the sites of the world can click “agree” to our terms, rather than the other way around.
Customer Commons is working on exactly those terms. The first publication to agree to readers terms is Linux Journal, where I am now editor-in-chief. The first of those terms is #P2B1(beta), says “Just show me ads not based on tracking me,” and is hashtagged #NoStalking.
In Help Us Cure Online Publishing of Its Addiction to Personal Data, I explain how this models the way advertising ought to be done: by the grace of readers, with no spying.
Obeying readers’ terms also carries no risk of violating privacy laws, because every pub will have contracts with its readers to do the right thing. This is totally do-able. Read that last link to see how.
As I say there, we need help. Linux Journal still has a small staff, and Customer Commons (a California-based 501(c)(3) nonprofit) so far consists of five board members. What it aims to be is a worldwide organization of customers, as well as the place where terms we proffer can live, much as Creative Commons is where personal copyright licenses live. (Customer Commons is modeled on Creative Commons. Hats off to the Berkman Klein Center for helping bring both into the world.)
I’m also hoping other publishers, once they realize that they are no less a part of the surveillance economy than Facebook and Cambridge Analytica, will help out too.
[Later…] Not long after this post went up I talked about these topics on the Gillmor Gang. Here’s the video, plus related links.
I think the best push-back I got there came from Esteban Kolsky, (@ekolsky) who (as I recall anyway) saw less than full moral equivalence between what Facebook and Cambridge Analytica did to screw with democracy and what the New York Times and other ad-supported pubs do by baring the necks of their readers to dozens of data vampires.
He’s right that they’re not equivalent, any more than apples and oranges are equivalent. The sins are different; but they are still sins, just as apples and oranges are still both fruit. Exposing readers to data vampires is simply wrong on its face, and we need to fix it. That it’s normative in the extreme is no excuse. Nor is the fact that it makes money. There are morally uncompromised ways to make money with advertising, and those are still available.
Another push-back is the claim by many adtech third parties that the personal data blood they suck is anonymized. While that may be so, correlation is still possible. See Study: Your anonymous web browsing isn’t as anonymous as you think, by Barry Levine (@xBarryLevine) in Martech Today, which cites De-anonymizing Web Browsing Data with Social Networks, a study by Jessica Su (@jessicatsu), Ansh Shukla (@__anshukla__) and Sharad Goel (@5harad)
of Stanford and Arvind Narayanan (@random_walker) of Princeton.
(Note: Facebook and Google follow logged-in users by name. They also account for most of the adtech business.)
One commenter below noted that this blog as well carries six trackers (most of which I block).. Here is how those look on Ghostery:

So let’s fix this thing.
[Later still…] Lots of comments in Hacker News as well.
[Later again (8 April 2018)…] About the comments below (60+ so far): the version of commenting used by this blog doesn’t support threading. If it did, my responses to comments would appear below each one. Alas, some not only appear out of sequence, but others don’t appear at all. I don’t know why, but I’m trying to find out. Meanwhile, apologies.
{kind=link}
Leave a Reply