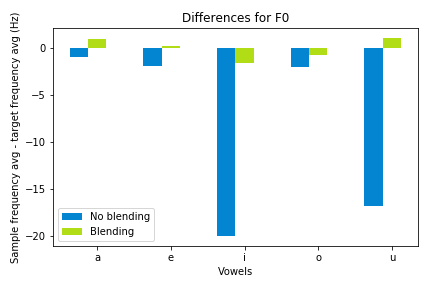
F0
Surprisingly, asking participants to blend led to their pitch getting closer to mine. Blend is different from intonation, and as an a cappella group we distinguish between these two factors, and yet it’s very interesting to see that these factors are connected. My guess is that “blending” is overall trying to sound more like those you’re singing with, and people (perhaps even unconsciously) tune their pitch as well as their vowels to the given note. This likely has to do with the fact that all formants have to do with harmonics of the waves creating the sounds, like we learned in class, so not only the vowel quality is impacted when people alter the waveforms of the sounds they produce.
F1
For every vowel, blending on average led to a decrease in the difference between the sample frequency and the target frequency for every vowel when you consider F1. This is very fascinating, since I remember from my phonetics class that F1 corresponds roughly to the pharynx, meaning that this may be the articulator that singers change when they’re trying to blend to a specific vowel. Also, both /o/ and /u/ are closer to the target frequency then their unrounded, fronted counterparts, suggesting that backness and/or roundedness may be correlated with higher blend.

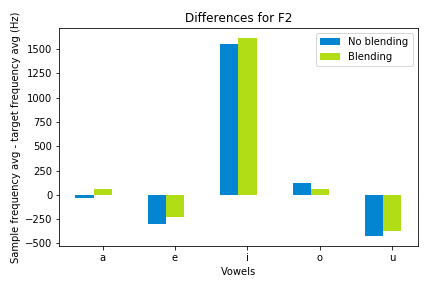
F2 and F3
Both F2 and F3 don’t seem to follow super clear trends in terms of which vowels blend best, except for the fact that /i/ on average had the worst blend by far when you consider F2, and /e/ had quite bad blending in F3. This may contribute to the idea that unrounded vowels are worse for blending, though that’s very unclear from the data at hand. Additionally, in both of these formants, some of the attempts at blending led to averages further from the non-blended attempts, meaning that they may not be great indicators for blend. Of course, this is under the assumption that the participants were actually blending, and that term was not defined for participants. They were just asked to “blend,” and occasionally I would clarify with something like, “try to sound like the recording.”