In spite of my heroic efforts—dragging myself to work on labor day, an achievement that required forsaking a morsel of socialist integrity—my attempts at setting up another overnight run of the FIB were thwarted by a “suppressor below limit” warning, which made obtaining any sort FIB image an impossibility. Thereby rendering the whole exercise impossible from the get-go. The upside was that I regained my labor day, the downside that I have nothing new to report from the FIB.
This morning I bit the bullet and finally replied to Dave’s email, meanwhile a week old, apologizing profusely for any offense I may have caused in my request of the full Neptune database, and proffering up my effusive thanks for the file he did provide. I’ll discuss the situation with Andy in our next meeting (perhaps Friday?) and see what he says, besides of course trying to decipher whatever runes constitute Dave’s reply.
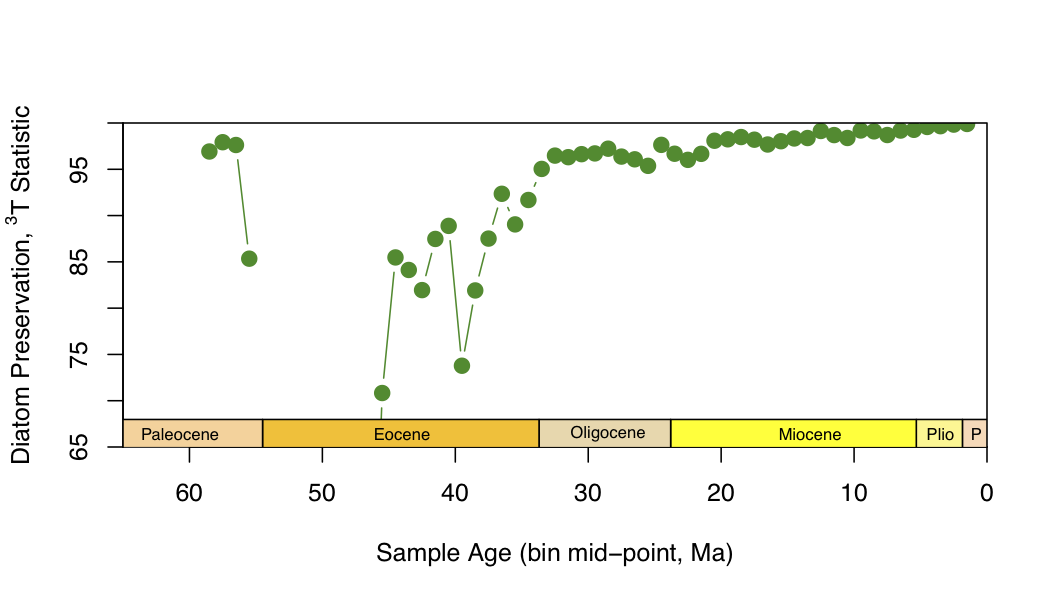
I decided to return to Friday’s question of the three-timer statistic, which turned out so differently than I had expected. Did I do something wrong with it? I thought I might compare my curve to what’s in the Rabosky paper, but in his supplements, the only thing he shows is the sampling probability for each of the subsampling exercises (rather than the overall sampling probability, as I have calculated, for the raw data).
If I didn’t do anything wrong, then the huge differences between the curves in my three-timer graph and the SIB/RT graph must lie in one- and two-timers, which I think is the only difference between the two counts. However, this difference would inflate the total diversity considered in SIB/RT and make the relative difference (between SIB and RT, analogous to the difference between 3T and 3T+PT) smaller… so, at the end of the day, the SIB/RT ratio should be higher than the 3T/(3T+PT) ratio. Which it isn’t! It’s lower, and a lot more variable. That variability I don’t think I can attribute to one- and two-timers, because any addition of those entities to the SIB count will also show up in the RT count, and vice versa.
Perhaps the way to tackle the question of whether the algorithm is actually doing what it’s supposed to do, I’m best off doing what I did with the SIB/RT algorithm: make sure the 3T and PT are being calculated properly by adding lines to the function to return those values along with the final %age. Did this, and couldn’t find much of anything out of the ordinary that would suggest something was going horridly wrong. The only low %ages are in time bins 47 and 48 (32% and 3%, respectively), everything else is above 70%. Unlike in the SIB/RT calculation. Here’s another view of the graph (same as last post’s), but with the x-axis expanded:
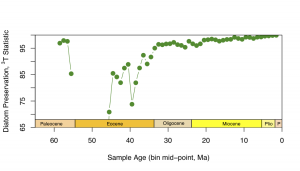
Don’t know what to do beyond this. It is what it is, report to Andy, move on? One final thing I could do, I suppose, is correct for the edge effects by comparing the focal bin to the adjacent time bins only, rather than comparing to everything before and everything after. Here’s the outcome (not much different, as is plainly clear):

Again, “preservation” (or “sampling probability”, as I think Alroy calls it) is pretty steady at between 95-100%, with some dips in the Eocene, and a little one in the early Miocene (which doesn’t show up in the long-range three-timer plot above, presumably because the missing taxa in the bins adjacent to the ~22 Ma time bin with the low %age are present elsewhere in the data set, from whence they can be ranged through).
The siren howled a little earlier this afternoon, in recognition of Beaudry’s imminent departure. It’ll be a tough start to the working day tomorrow knowing my DSA buddy is an ocean away. For today, I’m calling it quits.