Life Just Got Busy
ø
Since DSA yesterday afternoon. Once off the phone with Beau, I rushed home to get Kati ready for her flight to DC. Spent a much longer evening than usual working on the invitations—glue, ribbons, envelopes, calligraphy, etc—and didn’t get to bed until well after midnight. This morning, thought I’d be able to finish the rest in a quick whirl before work, but it ended up swallowing up most of the day and it was 3:30 by the time I finally made it to work via the post office to drop off the 72 beauties in their handwritten, bright yellow envelopes.
In the midst of the mounting stress over the upcoming meeting with Mike Foote, and the PlanktonTech report I have to write, and the status meeting with Andy to prepare for, and the résumé that needs putting together, and the R interface to finish up, I got an email from Dave Lazarus asking for comments on a paper he and John Barron are planning to submit to Nature. On—wait for it!—Cenozoic diatom diversity. Yes, believe it or not, I just got scooped once again. On work that I haven’t done yet, so I guess it’s not technically being scooped if it’s something you were thinking about doing someday but hadn’t gotten around to. Anyway, this is another thing on my plate and while I’m sure it’ll be fascinating to read it’s also another blow to my confidence for not getting that project done quickly, not to mention several hours next week down the drain at a time when I really need them. But, I also need Dave, so there’s no way I can blow him off—though I did email him back to ask how much feedback he wanted, and that I wouldn’t be able to provide much before late next week, because I’m busy. Humph.
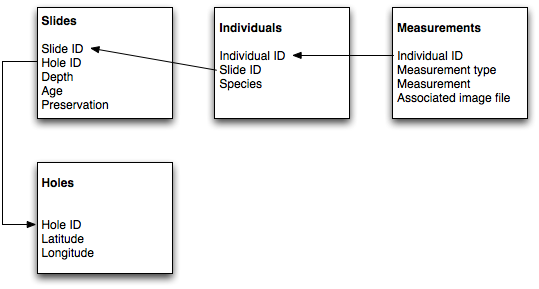
Anyway. Now that I’ve vented some time-crunch stress, I’ll get to the task I started (but didn’t finish) yesterday—putting the keystone pieces into the Bridge of Rads database interface. Once in place, we’ll see whether I can jump up and down on it without it crumbling into a sad pile of rubble, as the dust swirls around me.
Made some decent progress over the course of the afternoon, putting all the major pieces in place—but noticed that there were quite a lot of little pieces missing altogether. This is the downside of “sit down and code” rather than developing a very detailed plan of what the program’s going to look like… But whatever, it’s not an enormously complex piece of software, and I can figure out as I go along.
Left work at 7:15pm, by which point I’d gotten much of the way through—although I have yet to do a first test run of the whole interface to see if it all works… perhaps tomorrow?!