
The last two days of the Truthiness conference, co-hosted by the Berkman Center for the Internet & Society and MIT’s Center for Civic Media, exposed a rich cross-section of people, research, and applications dedicated to fighting misinformation in its many forms. We spent the day Tuesday discussing the wide world of facts and falsehoods, with an embarrassing collection of brains on hand to inform us on the history, cognitive psychology, and best practices of encouraging a healthy respect for reality. The challenge ahead, now that all the mini eclairs are gone, is to convert the goodwill, knowledge, and collaboration generated by this conference into a united front against delusion. Here’s my pitch.
On day two of the conference, we headed over to the Media Lab to get hacking. It was clear from day one of the conference that the nascent truthiness ecosystem was growing faster than any of us had realized. Consider these projects, which represent some of the organizations and applications working to bring credibility back to the web:

- TruthGoggles – Automatic bullshit detector that highlights permutations of factual or inaccurate claims wherever you go online. (represented at the table by Dan Schultz)
- LazyTruth – A gadget for your email inbox, which automatically surfaces pre-existing factual information when you receive misleading viral email forwards. (represented by myself, Matt Stempeck)
- FactSpreaders – A volunteer corps of people working to amplify facts in the fact of misinformation, as well as a tool to crowdsource the matching of myths and debunks. (represented by Paul Resnick)
- Spundge – A startup building research and contextual tools for news organizations, which could ensure reporters have access to higher quality information before a story is even published. (represented by Craig Silverman)
- MediaBugs – A service for correcting errors in media coverage after the fact.
- Hypothes.is – Peer review for the internet.
- Swiftriver – An interface that allows you to assign credibility weighting to incoming sources in a realtime environment with streams of social media and other sources. Part of the Ushahidi platform.
- Truthy – A research project studying how memes, and astroturf campaigns in particular, spread online.
Back at the hackathon, we shared a long list of exciting ideas and potential applications with one another. It soon became clear that we’d all benefit from shared standards (and corresponding API) as we track and link misinformation and verified rebuttals. In his talk the prior day, Craig Silverman had noted that, if there’s a tsunami of misinformation online, it would be great if all of the people and projects tracking it could signal to one another, like buoys in a Tsunami Early Warning System.
There could be many benefits to working together in a federated network. Talented developers are prevented from experimenting freely in this space because of the high barrier to entry that is hiring a team of researchers. Fact-checking outlets can’t possibly know, empirically, which internet fire most needs a dousing. The audience for traditional fact-checkers is also limited to their relatively small web and print readership. Together, we could do much more, and at greater scale.
Paul Resnick, Craig Silverman, Prathima Manohar, Dan Schultz, Eugene Wu, and myself huddled over pizza to figure out what a standardized service would look like. What would applications pull, and what could they contribute back to the common good?
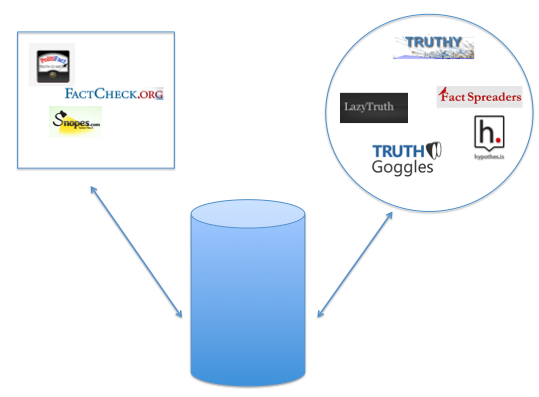
The fact-checking groups, and journalists and researchers in general, could provide dynamic access to thousands of known myths and linked debunks. The developers and designers could use this corpus across many other applications, which could pull what they need to respond to misinformation in creative ways in endless forums. Applications could consult verified facts, check claims they find across the web, and display where claims appear across the web.
Applications could also contribute back by completing a feedback loop. Users could flag suspicious claims across the web, essentially creating a public, quantified list for fact-checking groups to look into. Users could crowdsource the matching of myths and verified information. The various applications could also return critical metrics to help determine which, if any, of these tools are proving effective.
Yes, there are challenges. The good news is that several of the projects represented at our table are already taking on individual pieces of the above list of possibilities. But there are also several challenges to creating a shared standard, and recruiting the heavyweights of the fact-checking space to employ it. Ethan Zuckerman pointed out that the traditional problem with standards is that everyone ends up creating their own, but also noted that this is a space that’s well enough contained and defined that we might reach some common ground.
Of course, as we’ve seen with other APIs, funding the original work is a major concern, especially in an era of shrinking newsrooms. I’m a big believer in the potential of harnessing the wisdom of the crowd, but there are also times when a difficult, thankless task requires paying a reporter to do some research. It’s not clear that the apps mentioned here will produce enough revenue to directly support this work.
I’m heartened that at least several credibility app developers are already working together to improve what we know about the spread of misinformation online and to test the efficacy of factual interventions. And I’m hopeful that we can enlist the seasoned veterans in this space to create a shared web service, as it would improve all of our work. Teaming up could also get the fact-checking organizations’ work out in front of many more people, and possibly reach people in deeper, more effective ways than the current dominant format, the newspaper column.
What now? I hate to say it, but we probably need a working group, or something. Sound off in the comments if you’re on board. And I’m relatively new to this world, so please tell me what we’ve missed, too.
Images created (under tight deadline) by Craig Silverman.
This post was originally posted at http://civic.mit.edu/blog/mstem/lets-combine-forces-and-build-a-credibility-api on March 7, 2012.
Pingback: By the end of the year your browser could have a fact checker, just like your spell checker | Neurobonkers.com