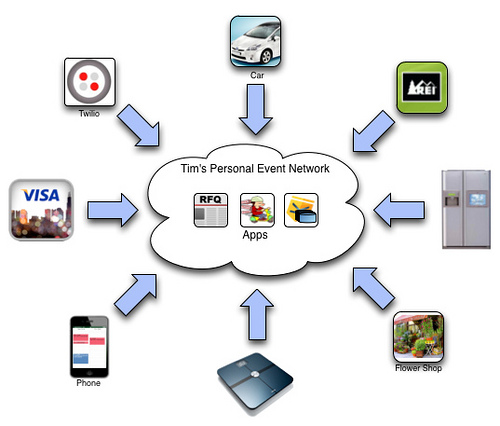
I’ll be having a brown bag lunch today with a group of developers, talking about VRM and personal clouds, among other stuff that’s sure to come up. To make that easier, I’ve copied and pasted the current list from the VRM developers page of the ProjectVRM wiki. If you’d like to improve it in any way, please do — either on the wiki itself, or by letting us know what to change.
While there are entire categories that fit in the larger VRM circle — quantified self (QS) and personal health records (PHRs) are two that often come up — we’ve tried to confine this list to projects and companies that directly address the goals (as well as the principles) listed on the main page of the wiki.
Here is a partial list of VRM development efforts. (See About VRM). Some are organizations, some are commercial entities, some are standing open source code development efforts.
| SOFTWARE and SERVICES |
| Intentcasting |
| AskForIt † – individual demand aggregation and advocacy |
| Body Shop Bids † – intentcasting for auto body work bids based on uploaded photos |
| Have to Have † – “A single destination to store and share everything you want online” |
| Intently † – Intentcasting “shouts” for services, in the U.K. |
| Innotribe Funding the Digital Asset Grid prototype, for secure and accountable Intentcasting infrastructure |
| OffersByMe † – intentcasting for local offers |
| Prizzm †- social CRM platform rewarding customers for telling businesses what they want, what they like, and what they have problems with |
| RedBeacon † – intentcasting locally for home services |
| Thumbtack † – service for finding trustworthy local service providers |
| Trovi intentcasting; matching searchers and vendors in Portland, OR and Chandler, AZ† |
| Übokia intentcasting† |
| Zaarly † intentcasting to community – local so far in SF and NYC |
| Browser Extensions |
| Abine † DNT+, deleteme, PrivacyWatch: privacy-protecting browser extentions |
| Collusion Firefox add-on for viewing third parties tracking your movements |
| Disconnect.me † browser extentions to stop unwanted tracking, control data sharing |
| Ghostery † browser extension for tracking the trackers |
| PrivacyScore † browser extensions and services to users and site builders for keeping track of trackers |
| Databases |
| InfoGrid – graph database for personal networking applications |
| ProjectDanube – open source software for identity and personal data services |
| Messaging Services and Brokers |
| Gliph †- private, secure identity management and messaging for smartphones |
| Insidr † – customer service Q&A site connecting to people who have worked in big companies and are willing to help when the company can’t or won’t |
| PingUp (was Getabl) †- chat utility for customers to engage with merchants the instant customers are looking for something |
| TrustFabric † – service for managing relationships with sellers |
| Personal Data and Relationship Management |
| Azigo.com † – personal data, personal agent |
| ComplainApp † – An iOS/Android app to “submit complaints to businesses instantly – and find people with similar complaints” |
| Connect.Me † – peer-to-peer reputation, personal agent |
| Geddup.com † – personal data and relationship management |
| Higgins – open source, personal data |
| The Locker Project – open source, personal data |
| Mydex †- personal data stores and other services |
| OneCub †- Le compte unique pour vos inscriptions en ligne (single account for online registration) |
| Paoga † – personal data, personal agent |
| Personal.com † – personal data storage, personal agent |
| Personal Clouds – personal cloud wiki |
| Privowny † – privacy company for protecting personal identities and for tracking use and abuse of those identities, building relationships |
| QIY † – independent infrastructure for managing personal data and relationships |
| Singly † – personal data storage and platform for development, with an API |
| Transaction Management |
| Dashlane † – simplified login and checkout |
| Trust-Based or -Providing Systems and Services |
| id3 – trust frameworks |
| Respect Network † – VRM personal cloud network based on OAuth, XDI, KRL, unhosted, and other open standards, open source, and open data initiatives. Respect Network is the parent of Connect.Me. |
| Trust.cc Personal social graph based fraud prevention, affiliated with Social Islands |
| SERVICE PROVIDERS OR PROJECTS BUILT ON VRM PRINCIPLES |
| First Retail Inc. † commodity infrastructure for bi-directional marketplaces to enable the Personal RFP |
| dotui.com † intelligent media solutions for retail and hospitality customers |
| Edentiti Customer driven verification of idenity |
| Real Estate Cafe † money-saving services for DIY homebuyers & FSBOs |
| Hover.com Customer-driven domain management† |
| Hypothes.is – open source, peer review |
| MyInfo.cl (Transitioning from VRM.cl) † |
| Neustar “Cooperation through trusted connections” † |
| NewGov.us – GRM |
| [1] † – Service for controlling one’s reputation online |
| Spotflux † malware, tracking, unwanted ad filtration through an encrypted tunnel |
| SwitchBook † – personal search |
| Tangled Web † – mobile, P2P & PDS |
| The Banyan Project– community news co-ops owned by reader/members |
| TiddlyWiki – a reusable non-linear personal Web notebook |
| Ting † – customer-driven mobile virtual network operator (MVNO – a cell phone company) |
| Tucows † |
| VirtualZero – Open food platform, supply chain transparency |
| INFRASTRUCTURE |
| Concepts |
| EmanciPay – dev project for customer-driven payment choices |
| GRM: Government Relationship Management – subcategory of VRM |
| ListenLog – personal data logging |
| Personal RFP – crowdsourcing, standards |
| R-button – UI elements for relationship members |
| Hardware |
| Freedom Box – personal server on free software and hardware |
| Precipitat, WebBox – new architecture for decentralizing the Web, little server |
| Standards, Frameworks, Code bases and Protocols |
| Datownia † – builds APIs from Excel spreadsheets held in Dropbox |
| Evented APIs – new standard for live web interactivity |
| KRL (Kinetic Rules Language) – personal event networks, personal rulesets, programming Live Web interactions |
| Kynetx † – personal event networks, personal rulesets |
| https://github.com/CSEMike/OneSwarm Oneswarm] – privacy protecting peer-to-peer data sharing |
| http://www.mozilla.org/en-US/persona/ Mozila Persona] – a privacy-protecting one-click email-based way to do single sign on at websites |
| TAS3.eu — Trusted Architecture for Securely Shared Services – R&D toward a trusted architecture and set of adaptive security services for individuals |
| Telehash – standards, personal data protocols |
| Tent – open decentralized protocol for personal autonomy and social networking |
| The Mine! Project – personal data, personal agent |
| UMA – standards |
| webfinger – personal Web discovery, finger over HTTP |
| XDI – OASIS semantic data interchange standard |
| PEOPLE |
| Analysts and Consultants |
| Ctrl-SHIFT † – analysts |
| Synergetics † – VRM for job markets |
| VRM Labs – Research |
| HealthURL – Medical |
| Consortia, Workgroups |
| Fing.org – VRM fostering organization |
| Information Sharing Workgroup at Kantara – legal agreements, trust frameworks |
| Pegasus – eID smart cards |
| Personal Data Ecosystem Consortium (PDEC) – industry collaborative |
| Meetups, Conferences, and Events |
| IIW: Internet Identity Workshop – yearly unconference in Mountain View |
| VRM Hub – meeting in LondonNOTES: † Indicates companies. Others are organizations, development projects or both. Some development projects are affiliated with companies. (e.g. Telehash and The Locker Project with Singly, and KRL with Kynetx.) A – creating standard B – Using other standards 1 – EventedAPI |



 The idea is to start getting real about what we’re all doing and not doing.
The idea is to start getting real about what we’re all doing and not doing.
 For as long as we’ve had economies, demand and supply have been attracted to each other like a pair of magnets. Ideally, they should match up evenly and produce good outcomes. But sometimes one side comes to dominate the other, with bad effects along with good ones. Such has been the case on the Web ever since it went commercial with the invention of the cookie in 1995, resulting in a
For as long as we’ve had economies, demand and supply have been attracted to each other like a pair of magnets. Ideally, they should match up evenly and produce good outcomes. But sometimes one side comes to dominate the other, with bad effects along with good ones. Such has been the case on the Web ever since it went commercial with the invention of the cookie in 1995, resulting in a 

 The
The