A lot has been happening in VRooMville lately. (Testimony: over there on the right at the moment we have three different #VRM tweets, in three different languages.) Rather than summarize things, I’ll let writers and developers in the VRM community give us a rundown. In no special order, here goes…
Reverse the Paradigm, by Uwe Hook. Excerpt:
What if we asked: How can we deliver a product/service that people want? We could stop the insane guessing game all of us are engaged in. We wouldn’t have to battle for the attention of people; they asked for our attention. That’s the basic idea of Vendor Relationship Management. I’ve written many times about VRM before.
What baffles me is that many people believe this is an utopian dream. “It’ll never happen.” They tend to forget, it’s already happening. Not in the marketing world yet but it happened to the publishing industry. The desire of people to get customized media whenever they want it lead to the sale of Newsweek for $1. And the sale of Huffington Post for $315 million. It changed the recording industry forever. Or, rather, wrecked it. People revolted against getting their information top-down. They wanted customization, filters and control. It was a quick transformation because Web 2.0 made publishing so easy for everyone.
What makes you think the same won’t happen to marketing and advertising?
The Customer is Center, by Tara Hunt. Excerpt:
THE BIG IDEA: “Cookies and tracking software? Who needs em? People are creating taste-signals daily with what they choose to buy. Why not let the customer go directly to the brand/vendor and get rid of this guesswork?”
C3 Commentary : Welcome to VRMville! by Dan Miller. Excerpt:
Adding VRM (Vendor Relationship Management) to the picture adds a more “user-centric” set of possibilities. Each person who generates all this metadata is also given adequate means to control release of the data or to attach terms and conditions governing how and to whom the information can be released. That’s where companies like Sing.ly and its closely related Locker Project come into play.
In Bridging the Marketing/Customer Care Divide – Thoughts from #C32011, Lou Dubois of The Social Customer wrote that “Dan Miller (@dnm54) and Greg Sterling (@gsterling) from Opus Research (@opusresearch) put on a unique, intimate and thought-provoking conference last week in San Francisco built around the challenges and opportunities facing different companies as they try to close the gap and get folks from marketing, customer service and PR to work towards the larger organizational strategy.” He added that one take-away was, “The next big step for Social CRM is VRM — and 2011 will mark it officially moving from theory to practice for most intelligent organizations.”
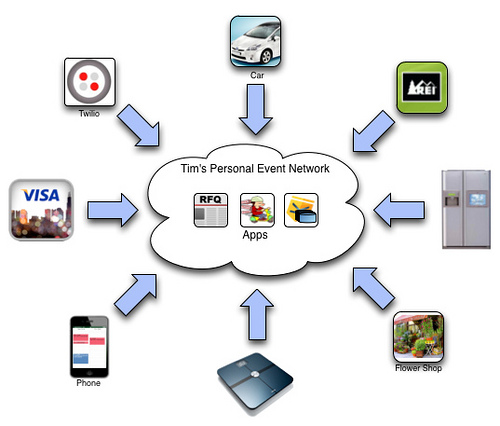
The Personal Cloud, by Drummond Reed. Excerpt:
When the VRM’rs on the panel first explained the concept of the personal data store, Mark Plakias, VP Strategy and Design at Orange Labs in San Francisco, immediately referred to it as the personal cloud. Although I’d heard the term a few times before, Mark’s usage suddenly rang true for me. He was referring to everything that the VRM community has traditionally defined a PDS as encompassing, plus personal storage, backup, connectivity, and other options that will clearly be part of the overall value proposition as the concept goes to market.
A little Google searching this weekend showed that a number of vendors including Iomega and Tonido are already using the term for cloud storage of personal data assets. And last May Forrester analyst Frank Gillette predicated that the personal cloud will replace the traditional personal computing OS.
That all seems to fit.
Then, The Personal Cloud, Take 2:
…neither the idea nor the term “personal cloud” is really new — all of this was 18 months ago. And the VRM community has been talking about personal data stores since 2004.
But, as with almost everything in tech, it’s all about timing. The Personal Data Ecosystem hadn’t formed yet. And, in my personal opinion, the technologies that can actually implement the personal control that all these authors agree will be necessary for personal clouds wasn’t there yet (hint: Internet identity is only the start). For example, Jeremie Miller hadn’t created the Locker Project or Telehash protocol yet, nor his new company Sing.ly based on it, which just won best-in-show at the O’Reilly Strata Conference Startup Showcase.
So maybe it’s finally time to seed personal clouds for real.
Then, Personal Cloud Take 3: Thomas Vander Wall’s Personal Infocloud:
When I first heard the term “personal cloud” from Mark Plakias at C3, I knew it sounded vaguely familiar, but it wasn’t until I started this series of blog posts that Kaliya Hamlin (Identitywoman) reminded me that Thomas Vander Wal named his blog Personal InfoCloud some years ago. Instantly I recalled the dinner that Kaliya and Thomas and I had in Washington D.C. a few years ago wheree he explained his vision for a personal information cloud, and how it was a superset of what the VRM community has been calling a personal data store.
In retrospect, I am quite sure this was one reason a subconscious bell rang for me when the term “personal cloud” came up again. And, reading recent posts from Thomas’ blog, including one about lessons to be learned from Yahoo’s threat to close Delicious, I point to it as even more evidence that the term works well for expressing what we all mean by this collection of personal data and relationships that will become the hub of your digital life.
Speaking of hubs, that reminds me of yet another pioneer thinker in this space: Jon Udell and his concept of hosted lifebits.
Riftstalker‘s VRM vs. RPG Excerpt:
When Doc Searls couldn’t explain what VRM is, he turned to RPGs. Wait, what’s VRM? VRM stands for Vendor Relationship Management.
So, as I was explaining VRM to some people this morning, and how we were equipping individuals with tools for both independence and engagement, an analogy came up: role playing games. Dungeons & Dragons. World of Warcraft. Final Fantasy.
I was blown away. Not because it’s a great analogy, but because I … just didn’t know. I’ve never played any of these games. But the people I was talking to had (or still did) play these games. And they were getting something about VRM that I wasn’t saying.
Well, Doc, RPGs get immediate response. Often emotional and sometimes even dramatic. Everyone has their favorite archetype, everyone has their favorite game. So who knows, maybe it’s like talking about your vendors… the Warrior vendor, the Mage vendor, and of course, the Rogue vendor.
Startups in the personal data ecosystem, by Kaliya Hamlin The list (all of which are also in the VRM space):
Data Storage, Collection and Sharing
Mydex is a Community Interest Company based in the UK that has begun a community prototype that connects individuals’ personal data store accounts to local government agencies.
Personal.com has raised 7 million in venture funding and although it does not yet have any services their website articulates clearly how personal data under the control of the user is valuable.
Singly Jeremy Miller’s startup to build 3rd and 4th party apps based on data from data stores build using the Locker Project code base an open source project for collating, securing and sharing personal data .
Statz is a startup that supports you pulling in your information from different service providers including Mobile phone record, Energy and utility records, Health and fitness, Shopping and payment, Transportation. Statz gives you instructions on how to go into your mobile carrier or electric company and export your statements – often this involves a dozen steps and is very labor intensive – not something easy or that everyone will do.
Greplin Does Personal Cloud SearchWhen people set up their accounts they give the service access to a range of accounts – LinkedIn, Gmail, Basecamp, Flickr, etc. Then you use their engine to search across them.
Backupify is an all-in-one archiving, search and restore service for the most popular online services including Google Apps, Facebook, Twitter, Picasa and more.
Switchbook helps manage user-driven searches across multiple search providers and websites, creating a powerful new way to explicitly express search intent anywhere on the Internet. Joe Andrieu
Trust Fabric provides Vendor Relationship Management (VRM) infrastructure. Businesses use CRM to manage customer relationships, while VRM lets individuals manage their relationships with businesses. TrustFabric writes Open Source software and gives customers a platform to represent their side of the VRM+CRM relationship. TrustFabric is based in Cape Town, South Africa.
Allow helps you to stop unwanted marketing and to get in control of the way your data is used.
Cloud Inc Consortium for Local Ownership and Use of Data, Inc. A non-profit technology standard consortia started in early 2009 that believes that a new era of ME 1.0 is at hand, an era that looks beyond Web 2.0, while simultaneously looking to the founding principles of the Internet as the solution to many of today’s most vexing issues of privacy, security and data.
Data Inherit DataInherit online safes from Switzerland offer individuals around the world highly secure online storage for passwords and digital documents. You can access your online safe using any Internet browser or an iPhone from anywhere and at any time. In addition the unique data inheritance functionality will protect your data in emergency situations. Simple and convenient.
New Application Building and Design Tools
Kynetx is developing a new language that looks at data from personal data stores and public datasets and can do real time matching based on rule sets created by the individual to surface relevant content.
Emancipay EmanciPay is a relationship management and voluntary payment framework in which buyers and sellers can present to each other the requirements and options by which they are willing to engage, or are already engaging. Including choices concerning payment, preference, policies.
Open Source Projects
The Higgins Project
Project Danube
The Locker Project
The MINE! Project
Project Nori
Speaking of Jeremie Miller, The Locker Project and Sing.ly, Marshall Kirkpatrick put the scoop in Creator of Instant Messaging Protocol to Launch App Platform for Your Life on ReadWriteWeb:
Called The Locker Project, the open source service will capture what’s called exhaust data from users’ activities around the web and offline via sensors, put it firmly in their own possesion and then allow them to run local apps that are built to leverage their data. Miller’s three person company, Singly, will provide the corporate support that the open source project needs in order to remain viable. I’m very excited about this project; Miller’s backgrounds, humble brilliance and vision for app-enabling my personal data history is very exciting to me.
Here’s how The Locker Project will work. Users will be able to download the data capture and storage code and run it on their own server, or sign up for hosted service – like WordPress.org and WordPress.com. Then the service will pull in and archive all kinds of data that the user has permission to access and store into the user’s personal Locker: Tweets, photos, videos, click-stream, check-ins, data from real-world sensors like heart monitors, health records and financial records like transaction histories.
Where data extraction is made easy already by APIs or feeds, Lockers will pull it that way. Where the data is appealing and the Locker community is motivated to do so, data connectors will be built.
Searching those data archives has been a technical challenge for many other startups, but the Locker team says it is trivial for them – because they only have to build search to scale across your personal data and the data you’ve been given permission to access by members of your network.
Seach and sharing across a user’s network will be powered by Miller’s eagerly-anticipated open source P2P project called Telehash, described as “a new wire protocol for exchanging JSON in a real-time and fully decentralized manner, enabling applications to connect directly and participate as servers on the edge of the network.”
… and here’s The Locker Project: data for the people in O’Reilly Radar:
Singly, by giving people the ability to do things with their own data, has the potential to change our world. And, as Kirkpatrick notes, this won’t be the first time Jeremie has done that.
I was drawn over to the Singly table when an awesome app they were demonstrating caught my eye. Fizz, an application from Bloom, was running on a locker with data aggregated from three different places.
Fizz is an intriguing early manifestation of capabilities never seen before on the web. It provides the ability for us to control, aggregate, share and play with our own data streams, and bring together the bits and pieces of our digital selves scattered about the web.
Managing Innovation, by Haydn Shaughnessy. Excerpt:
Personal data assets are fast becoming a new asset class, traded among these companies and marketing departments of enterprises around the world. That’s a shift in how personal data is conceived and exploited. The Vendor Relationship Management (VRM) community could bring another shift as start-ups begin invading this space, switching the emphasis to managing personal data assets on behalf of users.
Facebook as a personal data store, by Joe Andrieu. Excerpt:
To this veteran VRM evangelist, Facebook has done more in 2010 to usher in the era of the personal data store than anyone, ever. In one fell swoop, Facebook launched a World Wide Web built around the individual instead of websites, introducing the personal data store to 500 million people and over one million websites.
Unexpectedly, Facebook has moved VRM from a conversation about envisioning a future to one about deployed services with real users, being adopted by real companies, today. We still have a lot of work to do to figure out how to make this all work right—legally, financially, technically—but it’s illuminating and inspiring to see the successes and failures of real, widely-deployed services. Seeing what Amazon or Rotten Tomatos or Pandora do with information from a real personal data store moves the conversation forward in ways no theoretical argument can.
There remain significant privacy issues and far too much proprietary lock-in, but for the first time, we can point to a mainstream service and say “Like that! That’s what we’ve been talking about. But different!”
The Case Against Data Lock-In, by Brian W Fitzpatrick and JJ Lueck of Google’s Data Liberation Front in ACMQueue. Excerpt:
What Data Liberation Looks Like
At Google, our attitude has always been that users should be able to control the data they store in any of our products, and that means that they should be able to get their data out of any product. Period. There should be no additional monetary cost to do so, and perhaps most importantly, the amount of effort required to get the data out should be constant, regardless of the amount of data. Individually downloading a dozen photos is no big inconvenience, but what if a user had to download 5,000 photos, one at a time, to get them out of an application? That could take weeks of their time.
Even if users have a copy of their data, it can still be locked in if it’s in a proprietary format. Some word processor documents from 15 years ago cannot be opened with modern software because they’re stored in a proprietary format. It’s important, therefore, not only to have access to data, but also to have it in a format that has a publicly available specification. Furthermore, the specification must have reasonable license terms: for example, it should be royalty-free to implement. If an open format already exists for the exported data (for example, JPEG or TIFF for photos), then that should be an option for bulk download. If there’s no industry standard for the data in a product (e.g., blogs do not have a standard data format), then at the very least the format should be publicly documented—bonus points if your product provides an open source reference implementation of a parser for your format.
The point is that users should be in control of their data, which means they need an easy way of accessing it. Providing an API or the ability to download 5,000 photos one at a time doesn’t exactly make it easy for your average user to move data in or out of a product. From the user-interface point of view, users should see data liberation merely as a set of buttons for import and export of all data in a product.
Google is addressing this problem through its Data Liberation Front, an engineering team whose goal is to make it easier to move data in and out of Google products. The data liberation effort focuses specifically on data that could hinder users from switching to another service or competing product—that is, data that users create in or import into Google products. This is all data stored intentionally via a direct action—such as photos, e-mail, documents, or ad campaigns—that users would most likely need a copy of if they wanted to take their business elsewhere. Data indirectly created as a side effect (e.g., log data) falls outside of this mission, as it isn’t particularly relevant to lock-in.
Another “non-goal” of data liberation is to develop new standards: we allow users to export in existing formats where we can, as in Google Docs where users can download word processing files in OpenOffice or Microsoft Office formats. For products where there’s no obvious open format that can contain all of the information necessary, we provide something easily machine readable such as XML (e.g., for Blogger feeds, including posts and comments, we use Atom), publicly document the format, and, where possible, provide a reference implementation of a parser for the format (see the Google Blog Converters AppEngine project for an example1). We try to give the data to the user in a format that makes it easy to import into another product. Since Google Docs deals with word processing documents and spreadsheets that predate the rise of the open Web, we provide a few different formats for export; in most products, however, we assiduously avoid the rat hole of exporting into every known format under the sun.
GeekTown.ca‘s What if Flickr Fails? Excerpt:
Wouldn’t it be nicer to have a ‘bucket’ of storage where all your files are kept, and then make those files available to third party services that can add snappy interfaces, clever sharing mechanisms, tagging, and other Web 2.0 tools to the mix without touching the files directly?
That’s the concept now being floated by a growing collection of people that want to take back control of their data. Searls is working on ProjectVRM (vendor relationship management), which preaches self-hosting, among other things. Aleks Cronin-Lukas is working on the Mine! project, which advocates separating data owned by the user from third party applications. In models such as these, the data is stored in a single place on the Internet. The user can then expose that data to third party sites (like Flickr, etc), who can add functionality to it. But if the content site gets shut down, the original data is untouched. Another advantage to this concept is that the user can decide exactly what data gets shared, and how.
The VRM.CL folks have a post by Sebastian Reisch titled Otras maneras de definir VRM: la Nube Personal o Relaciones Manejadas por Consumidores, which Google Chrome translates to Other ways to define VRM: Personal Cloud or Managed by Consumer Relations. The translation, slightly edited:
…ultimately what we want to achieve with VRM is that each individual has an identity in the network by using myinfo.cl, and therefore has a personal space in the cloud… to keep your personal information that will help you to manage relationships with their suppliers. Ultimately to have a digital identity, which will receive the messages and offers that meet the needs we have at the right time.
…Ultimately, VRM is the application we’re building.. to lead consumers to take a more active role, and thus manage their relationships…
Also in ReadWriteWeb, Kynetx gets coverage in Nevermind Google, New Extensions Block Spam Across Browsers & Search Engines:
Yesterday, Google released a Chrome browser extension that lets users block certain websites from showing up in their Google search results. That way, if you never want to see an eHow article again, you don’t have to. Kynetx, a company that offers developers a single platform for building extensions for multiple browsers, saw the announcement and immediately offered $500 to the first person that could create an extension “with the same functionality for all 3 browsers and all 3 major search engines.”
Less than a day later, the company has announced a winner and released the extensions.
Those wishing to be involved in development efforts should also check out the Information Sharing Workgroup and UMA, the User Managed Access Work Group at Kantara.
Last but hardly least, both EmanciPay and Tipsy are in the second round of the Knight News Challenge. Go to those links and vote ’em up.
And if I’ve missed anything (and I’m sure I have), let me know and I’ll add it on.


 For as long as we’ve had economies, demand and supply have been attracted to each other like a pair of magnets. Ideally, they should match up evenly and produce good outcomes. But sometimes one side comes to dominate the other, with bad effects along with good ones. Such has been the case on the Web ever since it went commercial with the invention of the cookie in 1995, resulting in a calf-cow model in which the demand side — that’s you and me — plays the submissive role of mere “users,” who pretty much have to put up with whatever rules websites set on the supply side.
For as long as we’ve had economies, demand and supply have been attracted to each other like a pair of magnets. Ideally, they should match up evenly and produce good outcomes. But sometimes one side comes to dominate the other, with bad effects along with good ones. Such has been the case on the Web ever since it went commercial with the invention of the cookie in 1995, resulting in a calf-cow model in which the demand side — that’s you and me — plays the submissive role of mere “users,” who pretty much have to put up with whatever rules websites set on the supply side.

 The
The 

 Craig Burton
Craig Burton
 I have here at my left elbow an original 1993 edition of
I have here at my left elbow an original 1993 edition of 
