This blog post is an exposition of the presentation I gave at a Dev Staff, a Developer Community in Crete. This post approaches the matter from a high-level language perspective, just like my previous one on Rust.

Rust is a low-level language that has the trappings of a high-level language. Rust developers gleefully enjoy a modern, streamlined experience.
Fact of life – just like oxygen and Doritos – is that for a long long time there existed an orthogonal relationship between performance and memory safety. You could pick only one.
Rust feels like a managed language (e.g. Node, Ruby) but under-the-hood, it (like C/C++) is not. That is to say, Rust produces very performant software – it is really fast.
In order to achieve this feat, Rust has introduced some new ways of solving the good-ole problems – and it is the only non-academic language that has managed to do so. When it comes down to memory management, Rust is a huge innovator.

Rust disposes of the garbage collector but does not impose on the developer the burden of dealing with the memory garbage. Traditionally, you either have to manage the memory yourself (à la C), or pass the burden down to a run-time feature of the language – heroically called “the garbage collector“.
This means that within your executable there exists another software bundled, and that software is responsible for cleaning up the memory mess we create as the user enjoys our application.
While deferring the hard work to the garbage collector sounds fantastic (and it mostly is so), that comes with its own sets of problems. The biggest of said problems is that the garbage collector has the annoying habit to “pause the world”. The garbage collector literally stops the application execution to do the cleanup, and then magnanimously resumes it.
This can and does lead to loss of performance, which is bad in situations that depend on it. In general, the garbage collector is an inefficient beast.
Random unrelated image.
It is not just 60-frames-per-second games that long for high performance. Any CPU-bound or repeated process also requires it.
Suppose for a moment the UN Committee of Software Developer Experience mandated that Python is now the only legal programming language in the world to code with. Python is two Orders of Magnitude (100x) slower than C. Suddenly, your $3,000 MacBook Pro barely beats an early-1990s-era 386DX computer.
Performance matters in systems programming. Keeping the memory from blowing up not only prevents software crashes but also keeps the bad actors away from your personal data & financial assets. Therefore, we need both.

Before Rust, we relied on the genius of the developers to juggle inside their heads the two giant boulders of the application: the business domain and the security domain.
Experience (i.e. a multitude of bugs, exploits & hacks) has clearly demonstrated that this is not a good path to walk. This path has been walked only because historically it was the only path in existence. Not any more!
Memory Basics
Developers working with high level languages almost never need to come in contact with how their application memory is structured and its mechanics. For this reason, let’s do a quick and dirty overview of how it all works.
There are two memory kinds that are available for your beautiful Rust application to use.
The Stack
The stack has a rigid structure. This makes the stack is easy to reason with.
- Last-in, First-out.
- Data stored has fixed length.
You add (push) to the stack by adding to the top, and you remove (pop) from the stack by grabbing a plate from the top. Easy, peasy.
The stack is super fast and straightforward, but also limited in size. That’s because our applications can’t work only with data that can never be resized. For dynamically sized data (such as…, I don’t know…, useless things like Strings and Vectors), we need another type of memory.
The Heap
What is the heap? Is it something like this?

No, put aside all the fancy CS stuff for a moment and let’s get back to the fundamentals.
Which basically translates to this in your application memory:

The good part
You can mostly do whatever you want.
The bad part
You have to manage it or it will blow up.
But what exactly does memory management mean?
You must:
- Keep a mapping between the parts of code the data they use of the heap.
- Minimize data duplication.
- Cleanup unused data.
Ideally, you want your heap neat, tidy and pristine.

But that’s a lot of pain to do. We have AGILE constraints. We have to pair program, mob program, extreme program and get those pesky story points done before the sprint ends because the burnout chart must look a specific way.
So in high level languages we’re back to deferring to the garbage collector.
Unless we code in Rust.
But how does Rust do it?
To understand this, we need to explore some new concepts that Rusts brings into play.
Ownership
This is an easy concept to understand, but the effects it has on the way you approach problem solving may be a bit more complex.
The players
Ownership of what? Ownership of values.
Who owns values? Variables own values.
let x = 5;
x owns 5
The rules

The 3 rules of ownership are:
1. Thou shall not have a value without an owner.
2. Thou shall not have multiple owners for a single value.
3. Thou shall sacrifice the value in a pyre once its owner’s life has no scope left.
Wut?

Let’s begin with the last rule (translated in modern vernacular):
3. Out of scope, out of memory.
What is the problem with this code?
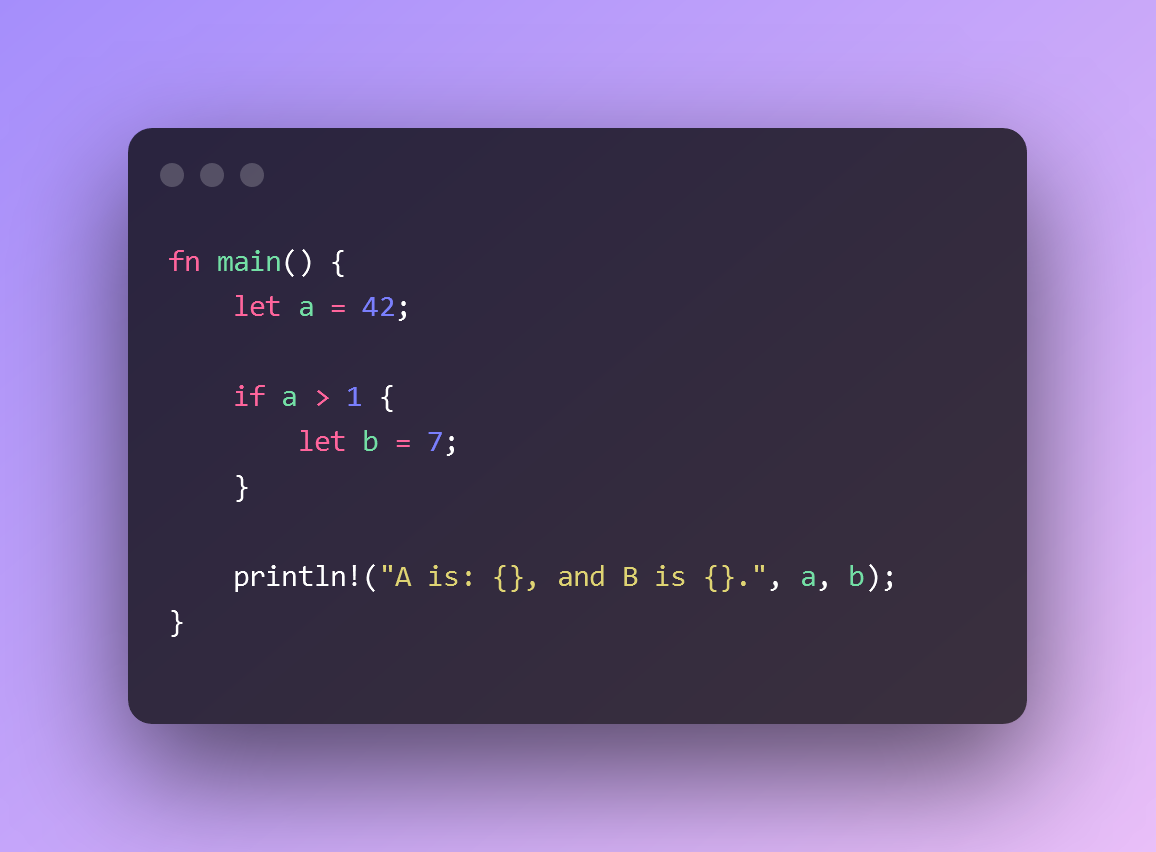
The problem is that it does not compile.
😮
I can loudly hear your righteously undignified screams. Why on Earth wouldn’t THIS compile?
The compiler is our friend. And the compiler stops us on println!, complaining that it:
cannot find value `b` in this scopeLet’s take a look at the code again, noticing the scope.
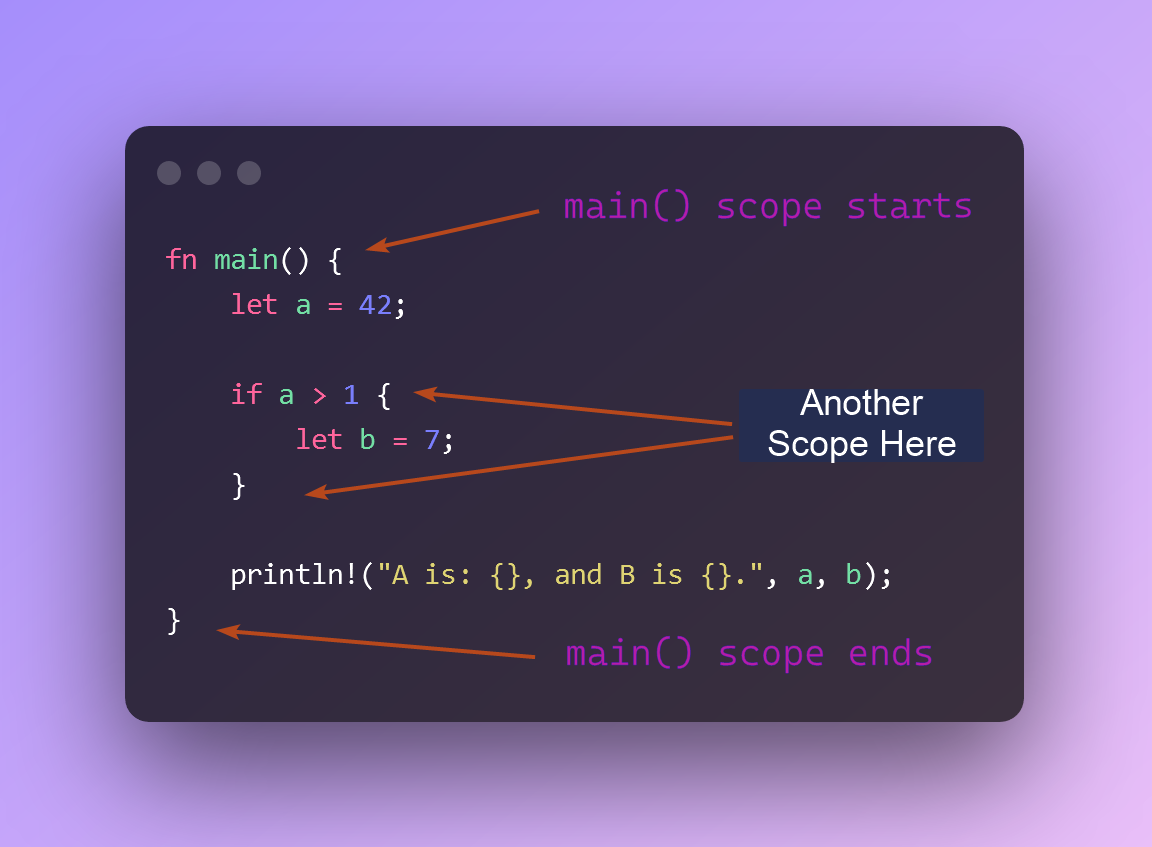
- The value 7 was owned by the variable b.
- The variable b lives only for the duration of the inner scope. It is gone from memory after that.
- Therefore, b does not exist when we try to reference it in println!()
The Rust compiler is a good butler. It wants to reduce our cognitive load. And there’s a lot of that involved on the art of making software. That is good. If something is trivial and doesn’t incur a cost, the compiler will do it on its own and hide that fact from us.

The hidden piece of action here is that the compiler tracked the variables scopes and then freed the values once each respected scope ended. We didn’t have to type drop() – and since we didn’t have to do it, it’s impossible to forget it by mistake.
Ok, sweet, nothing too radical here. Let’s move on.
2. One value, one ownER
Next question – what’s the problem with this code?

There is no problem, it compiles fine.
But you can’t compile it if your value is a string instead of a number.

Wtf?

This comes back to what we discussed earlier about the Stack and the Heap. The strings need dynamic allocation. You can append to a string. Therefore, they must live in the Heap.
Remember that one of the things we need to be mindful of when using the heap is to not perform unnecessary data duplication. So when we do let s2 = s, the compiler does NOT copy the memory value of “hello” into an new memory block. It simply creates a new pointer to the existing block in memory, like this:

OK, but why doesn’t it compile?
This code uses the Heap and we have two pointers referencing “hello” in memory. So what? Well, let’s go back to the rule we discussed.

That’s what we’d expect the compiler to do, right?
But the compiler refuses. Why?
It’s a double free condition! Basically, we enter undefined behavior territory. Which is bad. Really bad. So the compiler won’t let us do it.
The Burdens of Ownership
Unfortunately, this “no copy” strategy creates some troubling inconveniences, especially with passing values to functions. Functions have their own scope, just like the if {} block above.

This code won’t compile, because the ownership of the “hello” String value has moved from main() to foo().
Passing a variable to a function means moving its ownership. And that ownership doesn’t magically come back on its own after the function scope ends.
The naive solution is obvious (because why bother RTFM?). We can pass the ownership back and forth, like this:

Obviously, this doesn’t scale at all. We’re supposed to reduce our cognitive load, not increase it geometrically.

References & Borrowing
Naturally, Rust has a solution for that. It’s called temporary ownership, or “borrowing” for friends, with benefits.

This code now works. We told Rust that foo() needs to read the value of s but that we also need it back once it’s done. No interest needed. Just give it back.
But can I play with it?
Rust variables are immutable by default. But they don’t have to be. And the same goes for borrowed references.

The mut modifier marks the variable as mutable. And since we want foo() to be able to modify s as well, we need to explicitly let the compiler be aware of it. So we use &mut to pass a reference in a way that allows for modifying the value.
But – surprise! – there are rules for borrowing. And the compiler will enforce the rules – the tyrant that it is – so we should be aware of them.
So, within the same scope:
1a. One mutable borrow at a time.
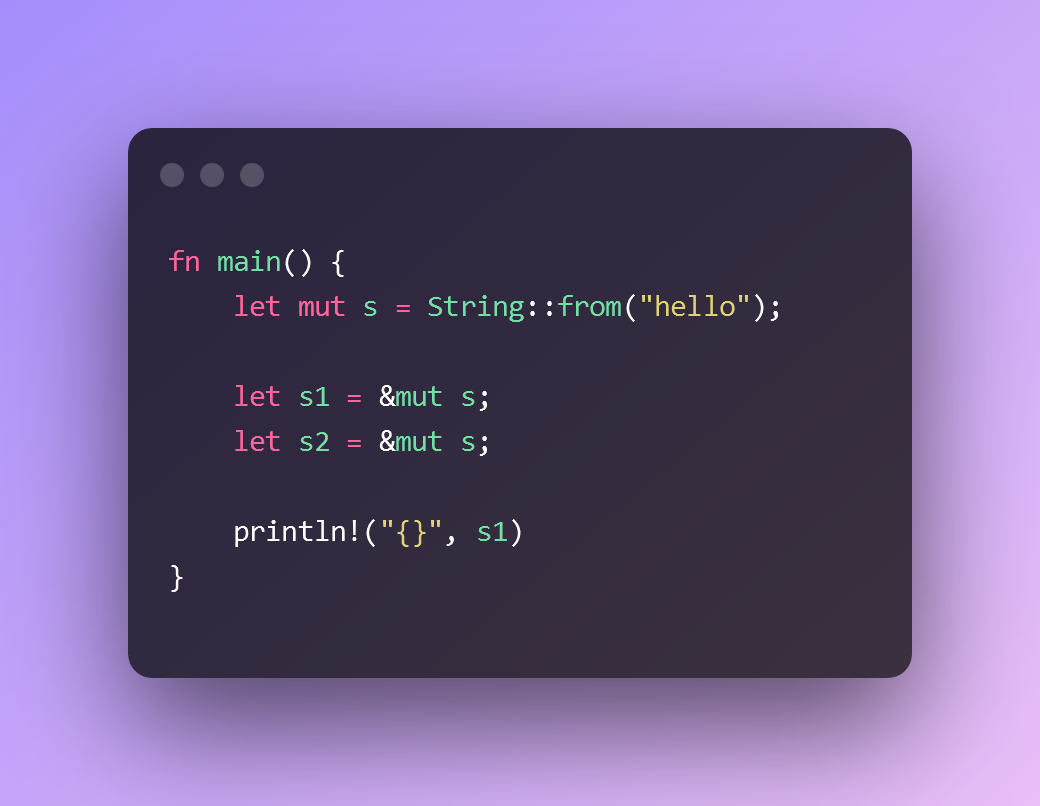
This will not compile. If it did, it could lead a race condition. Because there’s no mechanism used here for synchronizing access to the data value.
1A++.
It gets even worse: You can’t have read-only references at the same time with a mutable reference.
The code below works fine (mutable variable, no mutable borrowing, multiple read-only references):

The following though does not work:

Because we have a mutable reference to s and it must be the only reference to s.
So at any given time, you can have either one mutable reference OR any number of immutable references.
`1b. No Invalid References
An artistic depiction of a Dangling Pointer:

What is a dangling pointer? It’s a step to towards nothingness.
Let’s look at the example bellow:
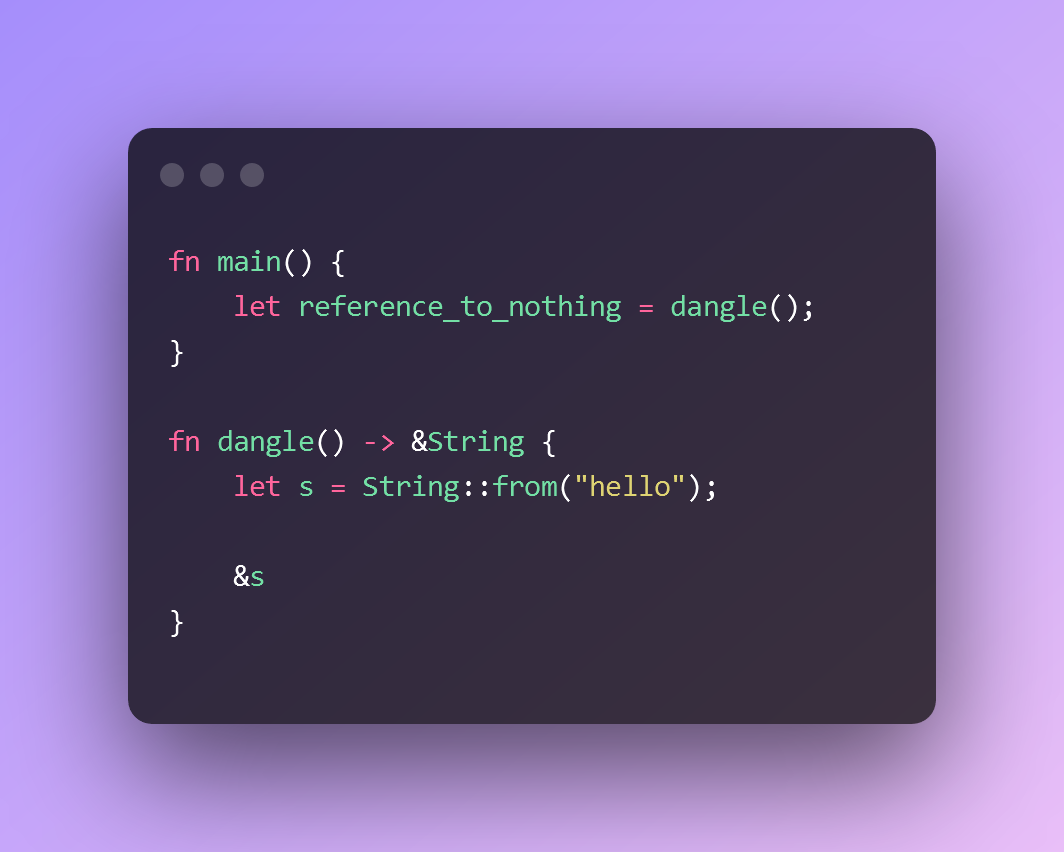
The dangle function creates a string value, owned by s.
Then it returns a reference to s. But remember that s goes out of scope once dangle() completes, so the value “hello” gets cleaned up from memory.
Then what does &s point to?
We will never know because the compiler refuses to build a binary. And the application users won’t get an exploitable binary.
Lifetimes
All the rules we’ve discussed so far are emerging properties of the Rust compiler’s inner workings. It’s like how you have rules for driving your car – they exist because of the nature of all the machinery under the hood.
While Ownership and Borrowing are fine concepts, they do not cover all cases. There are things that the compiler simply can’t infer based on those rules only. Even if it theoretically can do deeply nested inference, that is super super slow. So it won’t chose to.
In that case, it needs US – the benevolent, intelligent and beautifully handsome (or handsomely beautiful) programmers to give it a push.
But first, we need to dive into how the compiler works when it comes to borrowing – and talk about the concept of life.

Not that one exactly.
The compiler needs to keep track of where a variable MIGHT get used. In all the places in the code where that variable MIGHT get used, the variable is considered & marked as LIVE.
The same concept exists in Borrowing. A reference is LIVE at some parts of the code and … dead everywhere else.
An easy way to think about it is by looking at the lines of code. Obviously the compiler does not use “line of code” to reason about but it’s a good enough approximation for our purposes.

We note that:
x is LIVE on lines {1, 2, 3}.
r is LIVE on lines {2,3}
The set {1, 2, 3} is larger than the set {2,3}
Consider this though:

Here, things are a bit different:
x is LIVE on lines {3,4}
r is LIVE on lines {1,2,3,4,5,6}
r outlives x, but its value comes from a loan from x.
This is the dangling pointer issue we saw earlier.
The critical point (pun intended) here is that the compiler can reason about it. That’s because it has a way of figuring out when r & x are LIVE.
This area of code where a variable is LIVE, is called a lifetime.
OK, so we understand the compiler was able to calculate here the lifetime of a variable. But let us look at this code:

This code does not compile. Why not this time?
The problem is that the compiler can’t calculate the lifetime for the value of z (i.e. the return value of max()).
Is the lifetime of z related to the lifetime of s1 or the lifetime of s2? We can’t tell before runtime.
As an aside, yes, technically, we COULD have the compiler analyze all the calling cases of max() and have it decide that in this specific case, the lifetime of z should equal the lifetime of s1. And it would work for this toy code. Now imagine asking the compiler to do that for a real code-base. You'd be taking very very long compilation breaks.
Therefore the compiler stops and asks: “Oh mighty coder, shed your light here“.
The compiler wants us to enhance the function signature.
So we need a way to tell the compiler, “you know what, have the function require that the lifetime of its return value is related to s1 & s2 somehow“.
And we’ll do that by using lifetime annotations.
They look like generics and they’re ugly looking. Thankfully, we don’t have to use them often.

Hey, this compiles now! Sweet.
The compiler knows that the lifetime of the return value of max() MUST be such that matches s1 & s2.
Because the function now is expressively clear, the compiler can reason about the code main(). And in this case, the program compiles.
DO NOTE: Lifetime annotation does not enforce. It requires, in the sense of a contract. It’s up to the programmer to make sure the contract requirements hold when calling the function, lest the compiler throws a fit.
If main() was a bit different, the compiler would stop us.


The compiler stopped us from making a mistake because it knows exactly what the function max() needs in term of its parameter lifecycle.
Outro
Rust offers an innovative, breakthrough solution to the “Fast or Safe?” dilemma.
The good news
The compiler is there to help us.
The bad news
It takes a bit of practice to learn how to ride a bike well.
Is it worth it?
All in all, Rust is a fun and enjoyable systems programming language. It also happens to be fast & safe.
That’s not to say that Rust is the end-all-be-all of software development though. High-level languages thrive for good reasons. Rust’s domain isn’t the same and it doesn’t try to replace them. The Rust domain is the lower level applications and it does not pretend to conquer the world. Don’t use Rust to replace Python or Node because your productivity will take a hit. At least, for now. Rust lang is evolving and it may come a time that it does make sense to use it in the core domain of managed languages.
This is very well written. Thanks!
Excellent high level overview and the benefits of rust!
Coolest publish I’ve read about rust! Thanks you!
Excellent article. Explains the parts of Rust that are confusing to people coming from more traditional languages very well.
Thankies