For awhile the subhead at Customer Commons (our nonprofit spin-off) was this:

It’s still a timely thing to say, since searches on Google for “good customer” are at an all-time high:
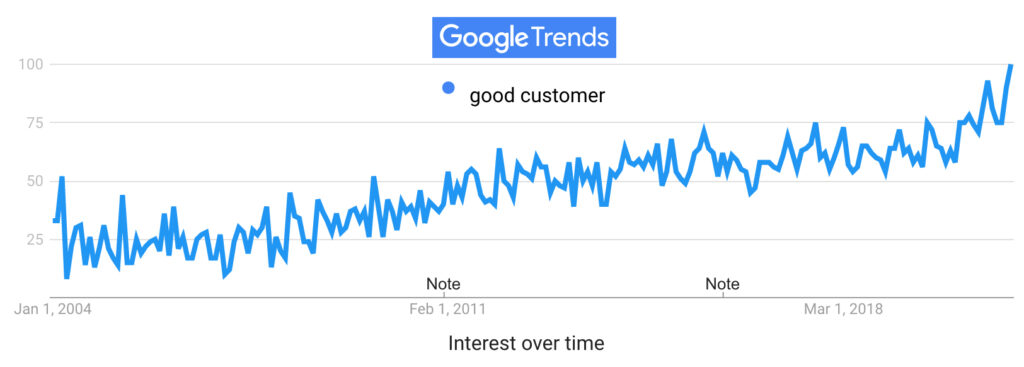
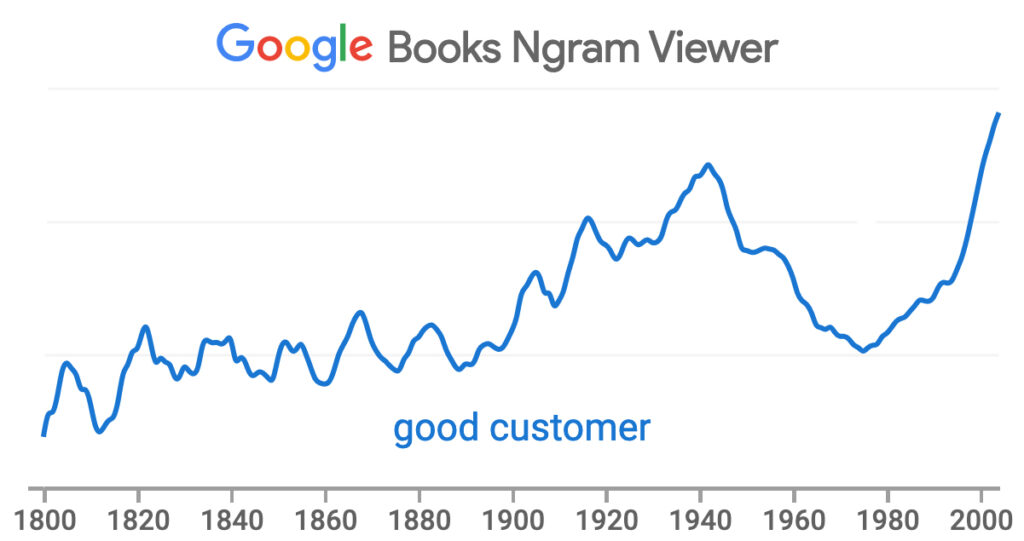
The year 2004, when Google began keeping track of search trends, was also the year “good customer” hit at an all-time high in percentage of appearances in books Google scanned*:
So now might be the time to ask, What exactly is a “good customer?
The answer depends on the size of the business, and how well people and systems in the business know a customer. Put simply, it’s this:
- For a small business, a good customer is a person known by face and name to people who work there, and who has earned a welcome.
- For a large business, it’s a customer known to spend more than other customers.
In both cases, the perspective is the company’s, not the customer’s.
Ever since industry won the industrial revolution, the assumption has been that business is about businesses, not about customers. It doesn’t matter how much business schools, business analysts, consultants and sellers of CRM systems say it’s about customers and their “experience.” It’s not.
To see how much it’s not, do a Bing or a Google search for “good customer.” Most of the results will be for good customer + service. If you put quotes around “good customer” on either search engine and also The Markup’s Simple Search (which brings to the top “traditional” results not influenced by those engines’ promotional imperatives), your top result will be Paul Jun’s How to be a good customer post on Help Scout. That one offers “tips on how to be a customer that companies love.” Likewise with Are You a Good Customer? Or Not.: Are you Tippin’ or Trippin’? by Janet Vaughan, one of the top results in a search for “good customer” at Amazon. That one is as much a complaint about bad customers as it is advice for customers who aspire to be good. Again, the perspective is a corporate one: either “be nice” or “here’s how to be nice.”
But what if customers can be good in ways that don’t involve paying a lot, showing up frequently and being nice?
For example, what if customers were good sources of intelligence about how companies and their products work—outside current systems meant to minimize exposure to customer input and to restrict that input to the smallest number of variables? (The worst of which is the typical survey that wants to know only how the customer was treated by the agent, rather than by the system behind the agent.)
Consider the fact that a customer’s experience with a product or service is far more rich, persistent and informative than is the company’s experience selling those things, or learning about their use only through customer service calls (or even through pre-installed surveillance systems such as those which for years now have been coming in new cars).
The curb weight of customer intelligence (knowledge, knowhow, experience) with a company’s products and services far outweighs whatever the company can know or guess at.
So, what if that intelligence were to be made available by the customer, independently, and in standard ways that worked at scale across many or all of the companies the customer deals with?
At ProjectVRM, this has been a consideration from the start. Turning the customer journey into a virtuous cycle explores how much more the customer knows on the “own” side of what marketers call the “customer life journey”†:
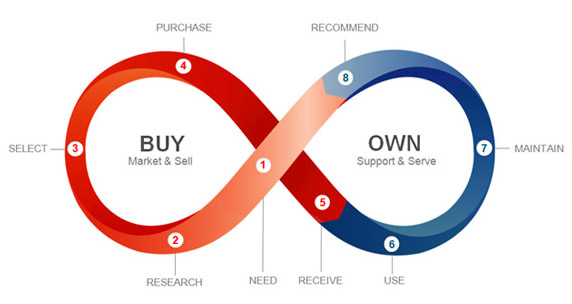
Given who much more time a customer spends owning something than buying it, the right side of that graphic is actually huge.
I wrote that piece in July 2013, alongside another that asked, Which CRM companies are ready to dance with VRM? In the comments below, Ray Wang, the Founder, Chairman and Principal Analyst at Constellation Research, provided a simple answer: “They aren’t ready. They live in a world of transactions.”
Yet signals between computing systems are also transactional. The surveillance system in your new car is already transacting intelligence about your driving with the company that made the car, plus its third parties (e.g. insurance companies). Now, what if you could, when you wish, share notes or questions about your experience as a driver? For example—
- How there is a risk that something pointed and set in the trunk can easily puncture the rear bass speaker screwed into the trunk’s roof and is otherwise unprotected
- How some of the dashboard readouts could be improved
- How coins or pens dropped next to the console between the front seats risk disappearing to who-knows-where
- How you really like the way your headlights angle to look down bends in the road
(Those are all things I’d like to tell Toyota about my wife’s very nice (but improvable) new 2020 Camry XLE Hybrid. )
We also visited what could be done in How a real customer relationship ought to work in 2014 and in Market intelligence that flows both ways in 2016. In that one we use the example of my experience with a pair of Lamo moccasins that gradually lost their soles, but not their souls (I still have and love them):

By giving these things a pico (a digital twin of itself, or what we might call internet-of-thing-ness without onboard smarts), it is not hard to conceive a conduit through which reports of experience might flow from customer to company, while words of advice, reassurance or whatever might flow back in the other direction:

That’s transactional, but it also makes for a far better relationship that what today’s CRM systems alone can imagine.
It also enlarges what “good customer” means. It’s just one way how, as it says at the top, good customers can work with good companies.
Something we’ve noticed in Pandemic Time is that both customers and companies are looking for better ways to get along, and throwing out old norms right and left. (Such as, on the corporate side, needing to work in an office when the work can also be done at home.)
We’ll be vetting some of those ways at VRM/CuCo Day, Monday 19 April. That’s the day before the Internet Identity Workshop, where many of us will be talking and working on bringing ideas like these to market. The first is free, and the second is cheap considering it’s three days long and the most leveraged conference of any kind I have ever known. See you there.
*Google continued scanning books after that time, but the methods differed, and some results are often odd. (For example, if your search goes to 2019, the last year they cover, the results start dropping in 2009, hit zero in 2012 and stay at zero after that—which is clearly wrong as well as odd.)
†This graphic, and the whole concept, are inventions of Estaban Kolsky, one of the world’s great marketing minds. By the way, Estaban introduced the concept here in 2010, calling it “the experience continuum.” The graphic above comes from a since-vanished page at Oracle.












.jpg){kind=link}